Mit git-history und Github Actions einen Scraper bauen
- DE
- EN
Web-Scraping setzt oft voraus, dass ein eigener Rechner verfügbar ist, welcher bestenfalls 24h online 🌐 ist und die Abfragen für das Scrapen absenden kann. Wenn wir das vermeiden wollen, beöntigen wir entsprechende Infrakstruktur. Simon Willison beschreibt in seinem Blogpost git-history ein Python Tool, welches aus einer Historie an git commits zu einer Datei, eine Zeitreihe erstellt. Diese Serie von git commits basieren auf einer speziellen Art zu scrapen. Dieses Pattern vereinfacht Web-Scraping, indem als Infrastruktur kein eigener Rechner genutzt werden muss, sondern Github actions. Die Github actions speichern jede neue unterschiedliche Version einer gescrapten Datei als eigenen commit im Repository.
Dieses Pattern wollte ich mit einer bis heute nur statischen Ressource ausprobieren, damit daraus für die Zukufnt eine Zeitreihe zum Analysieren entsteht. Diese statische Resource ist Teil des Datensatz des Parkleitsystems im Opendata Portal Frankfurt. Es haben sich schon mehr als 400 commits als Zeitreihe aus diesem Datensatz in diesem Repository angesammelt.
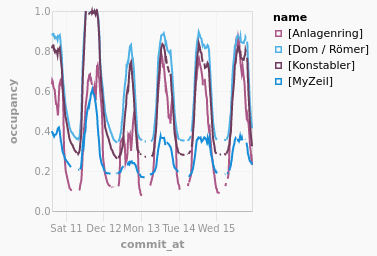
In der folgenden Abbildung ist die Parkauslastung in Prozent für die letzten Tage der Stadt Frankfurt am Main zu sehen.
Der Import der Historie via git-history kann an die eigenen Bedürfnisse angepasst werden.
Standardmäßig ist der Import von JSON vorgesehen.
Wenn etwas anderes als JSON importiert wird, definiere ich in einem per --convert-Flag übergebenen Skript den Code zum Ermitteln der Daten. Im Fall der XML-Parkdaten kann das folgendermaßen aussehen (nur Auszüge, das vollständige Skript findet sich hier):
git-history file ffm-parking.db parkdaten_dyn.xml --convert 'tree = xml.etree.ElementTree.fromstring(content)
# ...
areas = []
for el in tree[1][3][0].findall("{http://datex2.eu/schema/2/2_0}parkingAreaStatus"):
try:
areas.append({"id": e(el, "parkingAreaReference").get("id"),\
"occupancy": e(el, "parkingAreaOccupancy").text,\
return areas # ...
' --id id --import xml.etree.ElementTree
Auch standardmäßig werden z.B. nur die Änderungen zwischen zwei Versionen in einer Tabelle erfasst. Falls benötigt, kann auch der Import von allen Daten (nicht nur den Änderungen) veranlasst werden. Die nötigen Informationen sind ja glücklicherweise in der Historie vorhanden, müssen also nur zum Zeitpunkt des Imports aus der Historie ermittelt werden.
Unter dem Tag git-scraping haben sich einige Repositories angehäuft, zwar nicht alle mit derselben Methode, aber trotzdem stehen alle öffentlich bereit und sind bereit zum Visualisieren.
Update 12.05.2022: Leider hat das Opendata Portal Frankfurt den Datensatz seit ca. 17.12.2021 entfernt und bis heute nicht wieder hinzugefügt.